AI App Cost Savings Video Series
Practical patterns for reducing LLM costs in production apps
The series presents a developer‑focused video guide that explains concrete engineering patterns for lowering the cost of large‑language‑model (LLM) usage in production applications. It walks through common cost leaks such as selecting overly powerful models for simple tasks, making repeated identical calls, and inflating context windows with excessive prompts, history, or retrieved data. Each episode offers specific techniques—model routing by task, idempotency keys and request hashing, short‑lived caching, in‑flight deduplication, and batch processing—to mitigate these expenses without degrading performance.
Target audiences are engineers building AI‑powered services that have moved beyond prototypes and need to control operating margins. The content emphasizes that many cost issues stem from architectural decisions rather than model pricing alone, and it provides actionable steps for prompt management, caching strategies, reasoning settings, and workflow batching. By applying the recommendations, teams can reduce unnecessary LLM spend while maintaining functional quality.
Reviews
Loading reviews…
Similar apps
AI Coding Agents
KostAI
Cut LLM spend by up to 92 percent with governed routing
System Monitoring & Maintenance
AgenSights
Know exactly which AI agent is burning your budget.
AI Coding Agents
CodeRouter
Cut your AI coding bill 70% with automatic task routing

AI Coding Agents
Edgee Codex Compressor
Use Codex at 35.6% lower costs
Budgeting & Personal Finance
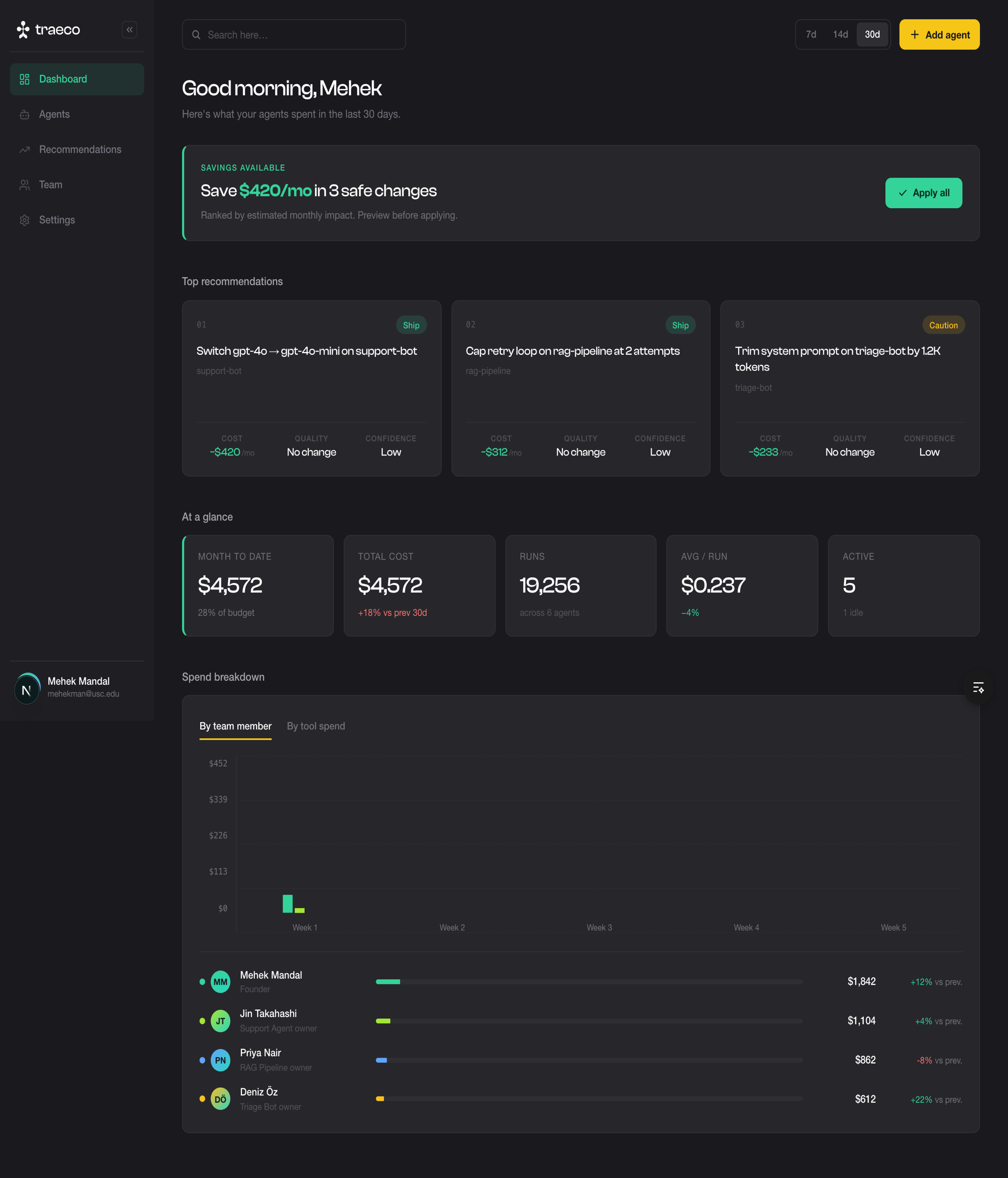
Traeco
Cost Optimization for AI Agents

AI Coding Agents
Langsmith
Observability platform for LLM applications, tracking prompts, latency, and costs.