KostAI
Cut LLM spend by up to 92 percent with governed routing
The project provides an open‑source, local‑first toolkit that inserts a control layer into any LLM‑powered workflow. It measures each AI call, routes the request to an appropriately sized model, applies compression or caching, and enforces quality gates before the token cost is incurred. The system is intended to be installed quickly without wizards or configuration files, allowing teams to run a pilot on a small workload and see a plain‑English report of savings.
It targets developers, operations teams, and product managers who need to manage token spend for AI agents, research assistants, or content‑generation pipelines. By offering voluntary “skills” that can be adopted per‑user or per‑team, it avoids mandatory telemetry or centralized monitoring, while still delivering auditability for managers.
What distinguishes the toolkit is its emphasis on measured pilots and proof‑before‑rollout, using a routing architecture that can reduce token costs by up to ninety‑two percent in demonstrated tests. The code is MIT‑licensed, hosted publicly on GitHub, and designed to integrate with existing LLM stacks without requiring a separate dashboard.
Reviews
Loading reviews…
Similar apps
AI Coding Agents
CodeRouter
Cut your AI coding bill 70% with automatic task routing
System Monitoring & Maintenance
AgenSights
Know exactly which AI agent is burning your budget.
AI Coding Agents
AI App Cost Savings Video Series
Practical patterns for reducing LLM costs in production apps
Budgeting & Personal Finance
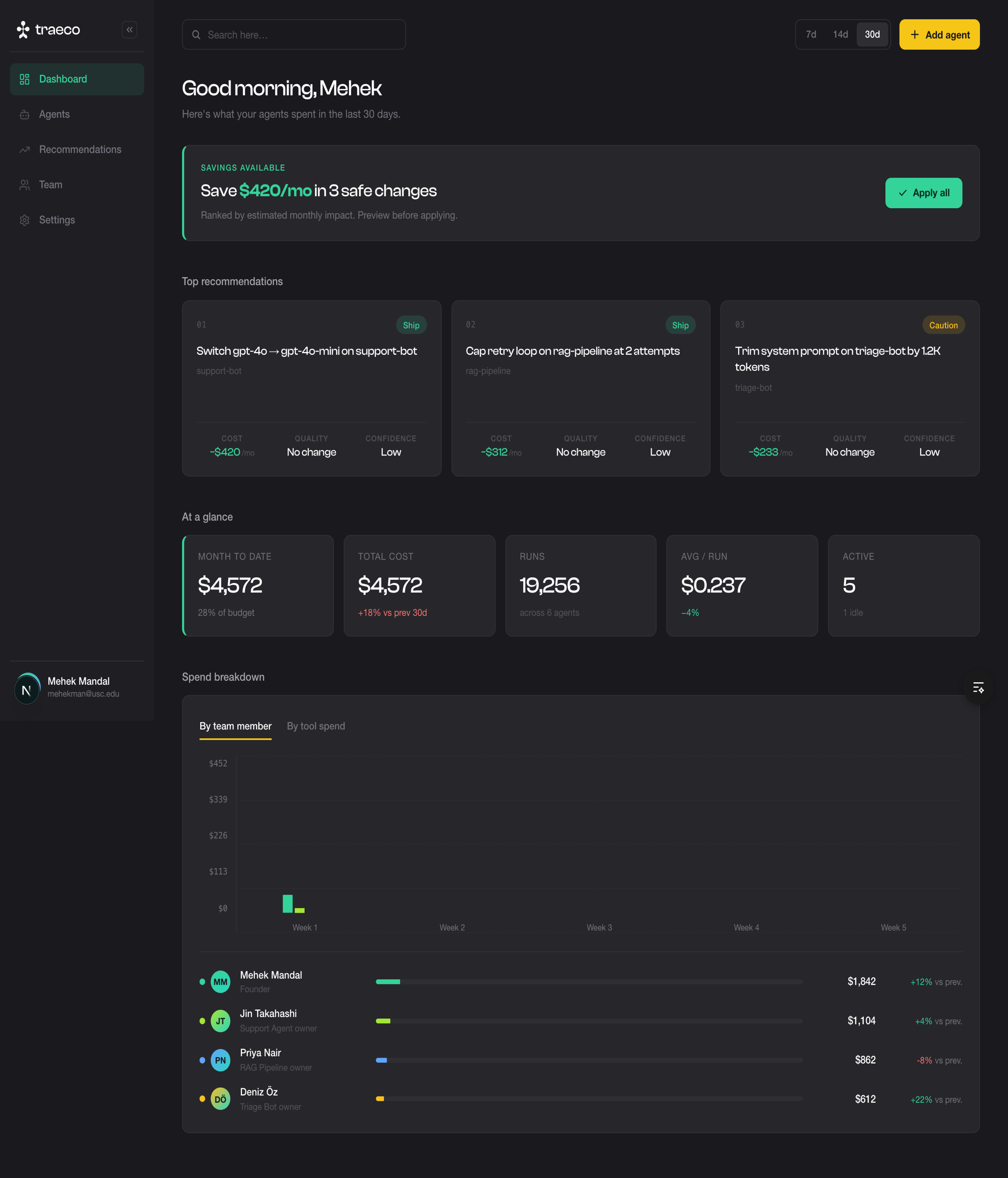
Traeco
Cost Optimization for AI Agents
DevOps & Infrastructure
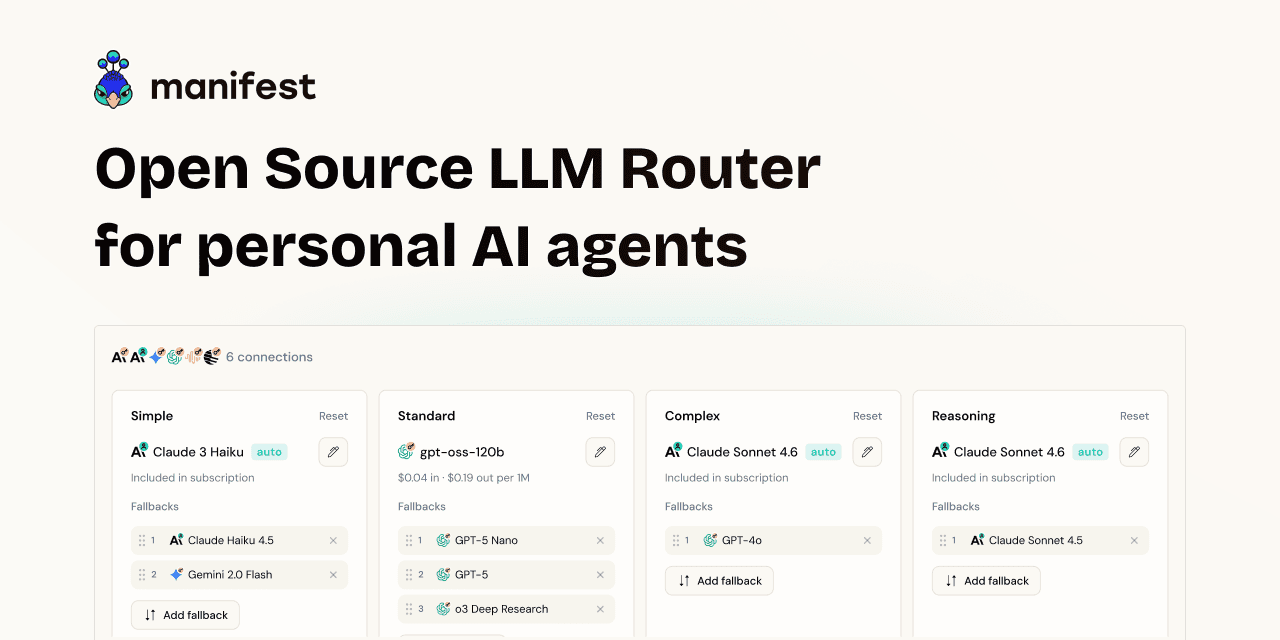
Manifest
Complete backend that fits into 1 YAML file.
AI Coding Agents
Korven
AI agents can act. But they have zero security